results <- data.frame(
Source = character(), Method = character(),
Events = numeric(), N = numeric(), stringsAsFactors = FALSE
)
# nSurv with all methods
for (m in c("LachinFoulkes", "Schoenfeld", "Freedman", "BernsteinLagakos")) {
x <- nSurv(lambdaC = lambdaC, hr = hr_design, gamma = 10, R = 12,
T = 36, minfup = 24, alpha = alpha, beta = beta, method = m)
results <- rbind(results, data.frame(
Source = "nSurv", Method = m, Events = x$d, N = x$n))
}
# gsDesign::nEvents (event count only, no N)
ne <- gsDesign::nEvents(hr = hr_design, alpha = alpha, beta = beta)
results <- rbind(results, data.frame(
Source = "gsDesign::nEvents", Method = "Schoenfeld", Events = ne, N = NA))
# rpact
d_fixed <- getDesignGroupSequential(kMax = 1, sided = 1, alpha = alpha, beta = beta)
for (tc in c("Schoenfeld", "Freedman")) {
ss <- getSampleSizeSurvival(d_fixed, hazardRatio = hr_design,
lambda2 = lambdaC, accrualTime = c(0, 12), followUpTime = 24,
typeOfComputation = tc)
results <- rbind(results, data.frame(
Source = "rpact", Method = tc, Events = ss$maxNumberOfEvents,
N = ss$maxNumberOfSubjects))
}
# gsDesign2 gs_design_ahr (k=1 fixed design) with 3 info_scale options
enroll_fix <- define_enroll_rate(duration = 12, rate = 10)
fail_fix <- define_fail_rate(duration = Inf, fail_rate = lambdaC,
hr = hr_design, dropout_rate = 0)
for (is in c("h0_h1_info", "h0_info", "h1_info")) {
x2 <- gs_design_ahr(enroll_rate = enroll_fix, fail_rate = fail_fix,
alpha = alpha, beta = beta, info_frac = 1, info_scale = is)
results <- rbind(results, data.frame(
Source = "gsDesign2 ahr", Method = is, Events = x2$analysis$event,
N = x2$analysis$n))
}
# gsDesign2 gs_design_wlr (k=1) with 3 info_scale options
for (is in c("h0_h1_info", "h0_info", "h1_info")) {
x_wlr <- gs_design_wlr(enroll_rate = enroll_fix, fail_rate = fail_fix,
weight = "logrank", alpha = alpha, beta = beta,
info_frac = 1, info_scale = is)
results <- rbind(results, data.frame(
Source = "gsDesign2 wlr", Method = is, Events = x_wlr$analysis$event,
N = x_wlr$analysis$n))
}
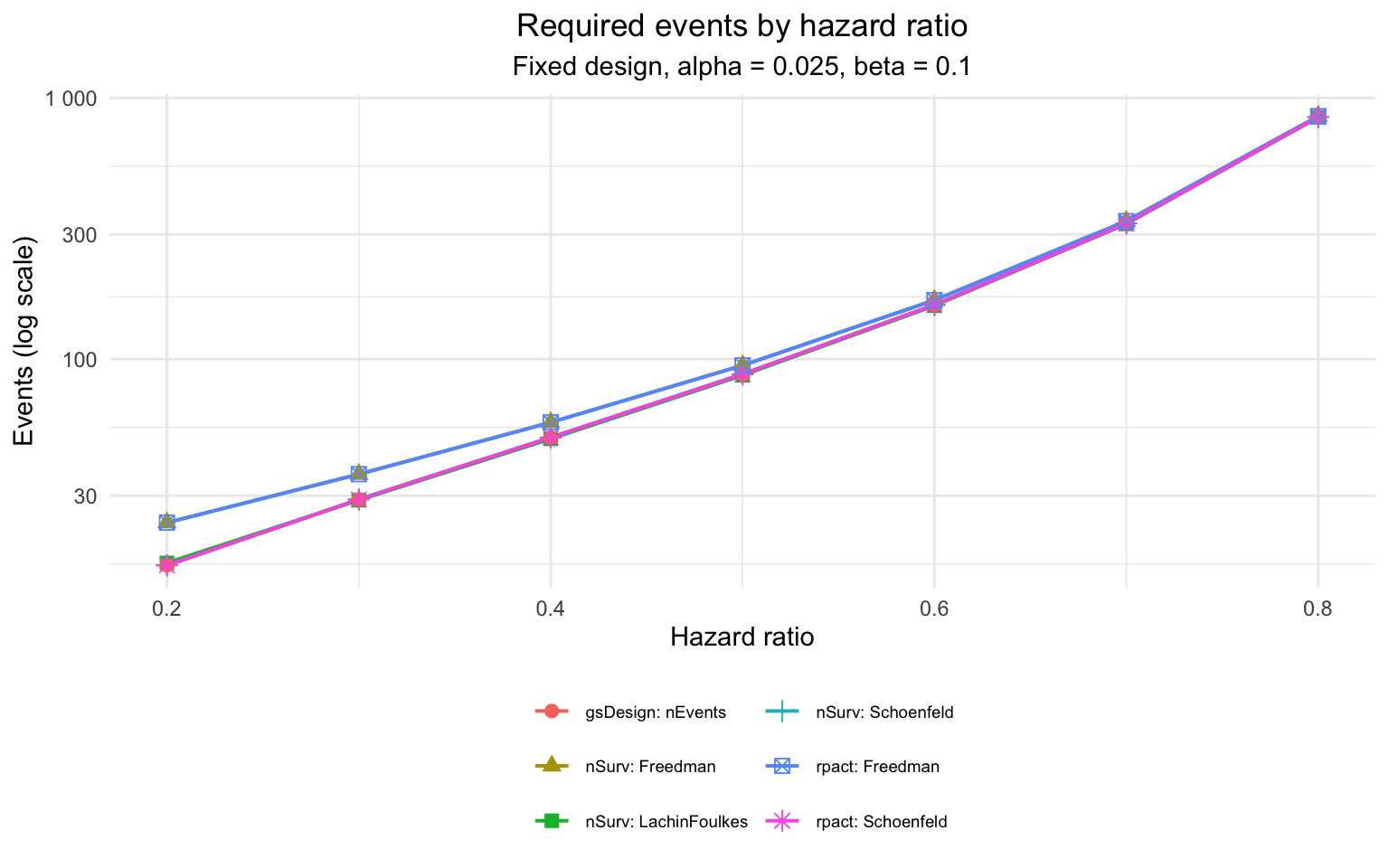
results |>
gt() |>
fmt_number(columns = c("Events", "N"), decimals = 1) |>
sub_missing(missing_text = "--") |>
tab_header(title = "Fixed-design sample size by method and package",
subtitle = "HR = 0.7, alpha = 0.025, beta = 0.1, ratio = 1") |>
tab_spanner(label = "Results", columns = c("Events", "N"))| Fixed-design sample size by method and package | |||
| HR = 0.7, alpha = 0.025, beta = 0.1, ratio = 1 | |||
| Source | Method |
Results
|
|
|---|---|---|---|
| Events | N | ||
| nSurv | LachinFoulkes | 329.2 | 433.3 |
| nSurv | Schoenfeld | 330.4 | 434.9 |
| nSurv | Freedman | 337.4 | 444.1 |
| nSurv | BernsteinLagakos | 316.5 | 416.5 |
| gsDesign::nEvents | Schoenfeld | 330.4 | – |
| rpact | Schoenfeld | 330.4 | 434.9 |
| rpact | Freedman | 337.4 | 444.1 |
| gsDesign2 ahr | h0_h1_info | 331.2 | 435.9 |
| gsDesign2 ahr | h0_info | 332.4 | 437.6 |
| gsDesign2 ahr | h1_info | 332.4 | 437.6 |
| gsDesign2 wlr | h0_h1_info | 325.8 | 428.8 |
| gsDesign2 wlr | h0_info | 330.7 | 435.3 |
| gsDesign2 wlr | h1_info | 330.7 | 435.3 |